
The Benefits of Indexing Foreign Keys
Primary and foreign keys are fundamental characteristics of relational databases, as originally noted in E.F. Codd’s paper, “A Relational Model of Data for Large Shared Data Banks”, published in 1970. The quote often repeated is, "The key, the whole key, and nothing but the key, so help me Codd."
Background : Primary Keys
A primary key is a constraint in SQL Server, which acts to uniquely identify each row in a table. The key can be defined as a single non-NULL column, or a combination of non-NULL columns which generates a unique value, and is used to enforce entity integrity for a table. A table can only have one primary key, and when a primary key constraint is defined for a table, a unique index is created. That index will be a clustered index by default, unless specified as a nonclustered index when the primary key constraint is defined.
Consider the Sales.SalesOrderHeader table in the AdventureWorks2012 database. This table holds basic information about a sales order, including order date and customer ID, and each sale is uniquely identified by a SalesOrderID, which is the primary key for the table. Every time a new row is added to the table, the primary key constraint (named PK_SalesOrderHeader_SalesOrderID) is checked to ensure that no row already exists with the same value for SalesOrderID.
Foreign Keys
Separate from primary keys, but very much related, are foreign keys. A foreign key is a column or combination of columns that is the same as the primary key, but in a different table. Foreign keys are used to define a relationship and enforce integrity between two tables.
To continue using the aforementioned example, the SalesOrderID column exists as a foreign key in the Sales.SalesOrderDetail table, where additional information about the sale is stored, such as product ID and price. When a new sale is added to the SalesOrderHeader table, it is not required to add a row for that sale to the SalesOrderDetail table However, when adding a row to the SalesOrderDetail table, a corresponding row for the SalesOrderID must exist in the SalesOrderHeader table.
Conversely, when deleting data, a row for a specific SalesOrderID can be deleted at any time from the SalesOrderDetail table, but in order for a row to be deleted from the SalesOrderHeader table, associated rows from SalesOrderDetail will need to be deleted first.
Unlike primary key constraints, when a foreign key constraint is defined for a table, an index is not created by default by SQL Server. However, it's not uncommon for developers and database administrators to add them manually. The foreign key may be part of a composite primary key for the table, in which case a clustered index would exist with the foreign key as part of the clustering key. Alternatively, queries may require an index that includes the foreign key and one or more additional columns in the table, so a nonclustered index would be created to support those queries. Further, indexes on foreign keys can provide performance benefits for table joins involving the primary and foreign key, and they can impact performance when the primary key value is updated, or if the row is deleted.
In the AdventureWorks2012 database, there is one table, SalesOrderDetail, with SalesOrderID as a foreign key. For the SalesOrderDetail table, SalesOrderID and SalesOrderDetailID combine to form the primary key, supported by a clustered index. If the SalesOrderDetail table did not have an index on the SalesOrderID column, then when a row is deleted from SalesOrderHeader, SQL Server would have to verify that no rows for the same SalesOrderID value exist. Without any indexes that contain the SalesOrderID column, SQL Server would need to perform a full table scan of SalesOrderDetail. As you can imagine, the larger the referenced table, the longer the delete will take.
An Example
We can see this in the following example, which uses copies of the aforementioned tables from the AdventureWorks2012 database that have been expanded using a script which can be found here. The script was developed by Jonathan Kehayias (blog | @SQLPoolBoy) and creates a SalesOrderHeaderEnlarged table with 1,258,600 rows, and a SalesOrderDetailEnlarged table with 4,852,680 rows. After the script was run, the foreign key constraint was added using the statements below. Note that the constraint is created with the ON DELETE CASCADE option. With this option, when an update or delete is issued against the SalesOrderHeaderEnlarged table, rows in the corresponding table(s) – in this case just SalesOrderDetailEnlarged – are updated or deleted.
In addition, the default, clustered index for SalesOrderDetailEnglarged was dropped and recreated to just have SalesOrderDetailID as the primary key, as it represents a typical design.
USE [AdventureWorks2012];
GO
/* remove original clustered index */
ALTER TABLE [Sales].[SalesOrderDetailEnlarged]
DROP CONSTRAINT [PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID];
GO
/* re-create clustered index with SalesOrderDetailID only */
ALTER TABLE [Sales].[SalesOrderDetailEnlarged]
ADD CONSTRAINT [PK_SalesOrderDetailEnlarged_SalesOrderDetailID] PRIMARY KEY CLUSTERED
(
[SalesOrderDetailID] ASC
)
WITH
(
PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF,
IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON
) ON [PRIMARY];
GO
/* add foreign key constraint for SalesOrderID */
ALTER TABLE [Sales].[SalesOrderDetailEnlarged] WITH CHECK
ADD CONSTRAINT [FK_SalesOrderDetailEnlarged_SalesOrderHeaderEnlarged_SalesOrderID]
FOREIGN KEY([SalesOrderID])
REFERENCES [Sales].[SalesOrderHeaderEnlarged] ([SalesOrderID])
ON DELETE CASCADE;
GO
ALTER TABLE [Sales].[SalesOrderDetailEnlarged]
CHECK CONSTRAINT [FK_SalesOrderDetailEnlarged_SalesOrderHeaderEnlarged_SalesOrderID];
GO
With the foreign key constraint and no supporting index, a single delete was issued against the SalesOrderHeaderEnlarged table, which resulted in the removal one row from SalesOrderHeaderEnlarged and 72 rows from SalesOrderDetailEnlarged:
SET STATISTICS IO ON;
SET STATISTICS TIME ON;
DBCC DROPCLEANBUFFERS;
DBCC FREEPROCCACHE;
USE [AdventureWorks2012];
GO
DELETE FROM [Sales].[SalesOrderHeaderEnlarged] WHERE [SalesOrderID] = 292104;
The statistics IO and timing information showed the following:
CPU time = 8 ms, elapsed time = 8 ms.
Table 'SalesOrderDetailEnlarged'. Scan count 1, logical reads 50647, physical reads 8, read-ahead reads 50667, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 2, logical reads 7, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'SalesOrderHeaderEnlarged'. Scan count 0, logical reads 15, physical reads 14, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 1045 ms, elapsed time = 1898 ms.
Using SQL Sentry Plan Explorer, the execution plan shows a clustered index scan against SalesOrderDetailEnlarged as there is no index on SalesOrderID:
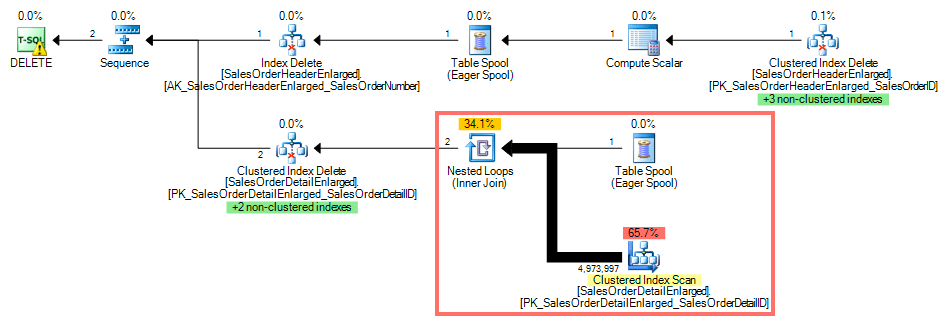
Query Plan with No Index on the Foreign Key
The nonclustered index to support SalesOrderDetailEnlarged was then created using the following statement:
USE [AdventureWorks2012];
GO
/* create nonclustered index */
CREATE NONCLUSTERED INDEX [IX_SalesOrderDetailEnlarged_SalesOrderID] ON [Sales].[SalesOrderDetailEnlarged]
(
[SalesOrderID] ASC
)
WITH
(
PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF,
ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON
)
ON [PRIMARY];
GO
Another delete was executed for a SalesOrderID that affected one row in SalesOrderHeaderEnlarged and 72 rows in SalesOrderDetailEnlarged:
SET STATISTICS IO ON;
SET STATISTICS TIME ON;
DBCC DROPCLEANBUFFERS;
DBCC FREEPROCCACHE;
USE [AdventureWorks2012];
GO
DELETE FROM [Sales].[SalesOrderHeaderEnlarged] WHERE [SalesOrderID] = 697505;
The statistics IO and timing information showed a dramatic improvement:
CPU time = 0 ms, elapsed time = 7 ms.
Table 'SalesOrderDetailEnlarged'. Scan count 1, logical reads 48, physical reads 13, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 2, logical reads 7, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'SalesOrderHeaderEnlarged'. Scan count 0, logical reads 15, physical reads 15, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 27 ms.
And the query plan showed an index seek of the nonclustered index on SalesOrderID, as expected:
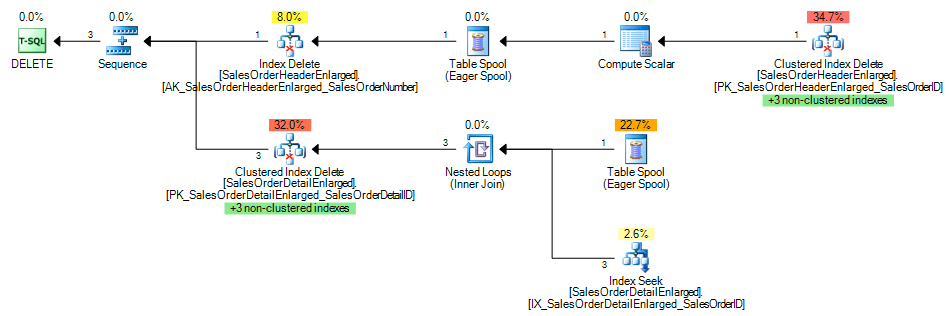
Query Plan with Index on the Foreign Key
The query execution time dropped from 1898 ms to 27 ms – a 98.58% reduction, and reads for the SalesOrderDetailEnlarged table decreased from 50647 to 48 – a 99.9% improvement. Percentages aside, consider the I/O alone generated by the delete. The SalesOrderDetailEnlarged table is only 500 MB in this example, and for a system with 256 GB of available memory, a table taking up 500 MB in the buffer cache doesn’t seem like a terrible situation. But a table of 5 million rows is relatively small; most large OLTP systems have tables with hundreds of millions rows. In addition, it is not uncommon for multiple foreign key references to exist for a primary key, where a delete of the primary key requires deletes from multiple related tables. In that case, it is possible to see extended durations for deletes which is not only a performance issue, but a blocking issue as well, depending on isolation level.
Conclusion
It is generally recommended to create an index which leads on the foreign key column(s), to support not only joins between the primary and foreign keys, but also updates and deletes. Note that this is a general recommendation, as there are edge case scenarios where the additional index on the foreign key was not used due to extremely small table size, and the additional index updates actually negatively impacted performance. As with any schema modifications, index additions should be tested and monitored after implementation. It is important to ensure that the additional indexes produce the desired effects and do not negatively impact solution performance. It is also worth noting how much additional space is required by the indexes for the foreign keys. This is essential to consider before creating the indexes, and if they do provide a benefit, must be considered for capacity planning going forward.
16 thoughts on “The Benefits of Indexing Foreign Keys”
Comments are closed.

Excellent post Erin. Very clear and concise. Thanks.
We had a detailed discussion on this here: http://sqlblog.com/blogs/greg_low/archive/2008/07/29/indexing-foreign-keys-should-sql-server-do-that-automatically.aspx
I've come to the conclusion that SQL Server would be better if it automatically indexed foreign keys unless you used the WITH I_KNOW_WHAT_IM_DOING option. Too many problems are caused by the lack of these indexes.
Thanks for reading Meher!
I remember reading that Greg, thanks for including the link! I think an option (say, instance-level) to automatically index foreign keys would be an interesting enhancement for the SQL Server to consider. Thanks for your comment!
Very nice and detailed sample on this common indexing problem. Want to read more :)
Nice post, Erin.
I'm always creating FK-indexes ( exactly matching the PK they refer to (col-order/sort) ) on all dbs that have FK-constraints until it's proven they hurt the system.
Then the will be disabled ( to keep it documented they have been in place and were disabled for a specific reason )
Good job on the article. :-)
Thanks Johan! I see why you keep the indexes around, but disabled. But, question for you…do you ever worry about the size the disabled FK-index consumes? Obviously it won't affect performance, but just wondering if you've ever found that they take up too much space.
Ha, yes, indeed they keep their space, wasted in the db and of course included with every full backup.
Should we submit a connect item for that ? If it's disabled, just handle the index like a table is being handled using a truncate statement ?
I've not been fortunate enough to work with TB db systems, as the matter of facts, I've only been asked to "remove" the FK-index on very few cases and those cases weren't on our largest db systems.
It took me some time ( couple of years ) to persuade the DBA of our ERP-software vendor to actually implement FKs and the corresponding indexes to support their data system. That actually got their software that much performance gain, they didn't drop any of the FK-indexes at all. :-)
That's an interesting idea for a connect item… When you truncate a table, the pages/extents are just deallocated, and it does the same for the indexes for the table. So theoretically, that code already exists (?). Might be worth filing.
I hope you captured data from before and after the FK and index changes – that's a nice case study to present to your developers :)
Yep, same here. I suggest people always create them during the design phase and only disable them when there is real proof that they are doing more harm than good.
As part of any health check, we look for a number of "code smells". One of these is any declared foreign keys where the key columns aren't the left-most columns in at least one non-clustered index.
Hey Johan, guess what? You're not using extra space in your database when you disable nonclustered indexes! No need to file a connect item, the pages are deallocated when you disable the NCI: http://msdn.microsoft.com/en-us/library/ms177456.aspx
What's really a kicker is that I blogged about it once… http://erinstellato.com/2010/12/disabling-indexes-saving-time-saving-space/
I'm getting old :)
Nice. easy to understand. Appreciate the efforts and Thanks for sharing.
This has helped me lot. Excellent post.
This was a very well written, informative post. The fact that you included a concrete example with before and after data was very helpful as well. Thanks!