
Should I use NOT IN, OUTER APPLY, LEFT OUTER JOIN, EXCEPT, or NOT EXISTS?
Let's say you want to find all the patients who have never had a flu shot. Or, in AdventureWorks2012, a similar question might be, "show me all of the customers who have never placed an order." Expressed using NOT IN, a pattern I see all too often, that would look something like this (I'm using the enlarged header and detail tables from this script by Jonathan Kehayias (@SQLPoolBoy)):
SELECT CustomerID
FROM Sales.Customer
WHERE CustomerID NOT IN
(
SELECT CustomerID
FROM Sales.SalesOrderHeaderEnlarged
);
When I see this pattern, I cringe. But not for performance reasons – after all, it creates a decent enough plan in this case:
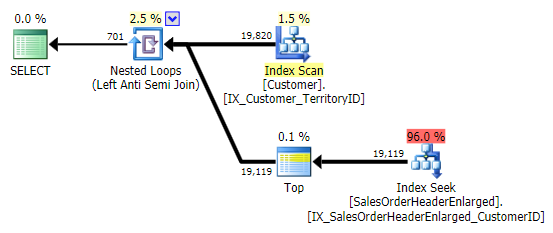
The main problem is that the results can be surprising if the target column is NULLable (SQL Server processes this as a left anti semi join, but can't reliably tell you if a NULL on the right side is equal to – or not equal to – the reference on the left side). Also, optimization can behave differently if the column is NULLable, even if it doesn't actually contain any NULL values (Gail Shaw talked about this back in 2010).
In this case, the target column is not nullable, but I wanted to mention those potential issues with NOT IN – I may investigate these issues more thoroughly in a future post.
TL;DR version
Instead of NOT IN, use a correlated NOT EXISTS for this query pattern. Always. Other methods may rival it in terms of performance, when all other variables are the same, but all of the other methods introduce either performance problems or other challenges.
Alternatives
So what other ways can we write this query?
OUTER APPLY
One way we can express this result is using a correlated OUTER APPLY.
SELECT c.CustomerID
FROM Sales.Customer AS c
OUTER APPLY
(
SELECT CustomerID
FROM Sales.SalesOrderHeaderEnlarged
WHERE CustomerID = c.CustomerID
) AS h
WHERE h.CustomerID IS NULL;
Logically, this is also a left anti semi join, but the resulting plan is missing the left anti semi join operator, and seems to be quite a bit more expensive than the NOT IN equivalent. This is because it is no longer a left anti semi join; it is actually processed in a different way: an outer join brings in all matching and non-matching rows, and *then* a filter is applied to eliminate the matches:
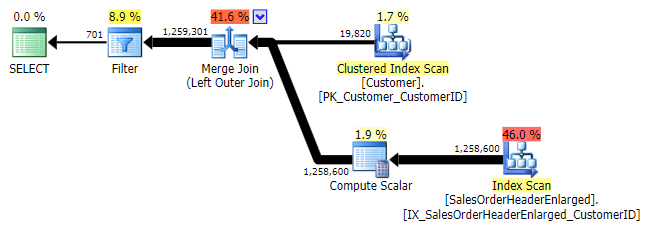
LEFT OUTER JOIN
A more typical alternative is LEFT OUTER JOIN where the right side is NULL. In this case the query would be:
SELECT c.CustomerID
FROM Sales.Customer AS c
LEFT OUTER JOIN Sales.SalesOrderHeaderEnlarged AS h
ON c.CustomerID = h.CustomerID
WHERE h.CustomerID IS NULL;
This returns the same results; however, like OUTER APPLY, it uses the same technique of joining all the rows, and only then eliminating the matches:
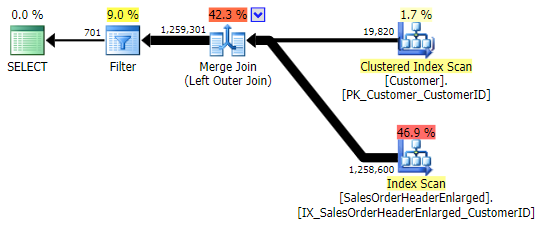
You need to be careful, though, about what column you check for NULL. In this case CustomerID is the logical choice because it is the joining column; it also happens to be indexed. I could have picked SalesOrderID, which is the clustering key, so it is also in the index on CustomerID. But I could have picked another column that is not in (or that later gets removed from) the index used for the join, leading to a different plan. Or even a NULLable column, leading to incorrect (or at least unexpected) results, since there is no way to differentiate between a row that doesn't exist and a row that does exist but where that column is NULL. And it may not be obvious to the reader / developer / troubleshooter that this is the case. So I will also test these three WHERE clauses:
WHERE h.SalesOrderID IS NULL; -- clustered, so part of index
WHERE h.SubTotal IS NULL; -- not nullable, not part of the index
WHERE h.Comment IS NULL; -- nullable, not part of the index
The first variation produces the same plan as above. The other two choose a hash join instead of a merge join, and a narrower index in the Customer table, even though the query ultimately ends up reading the exact same number of pages and amount of data. However, while the h.SubTotal variation produces the correct results:
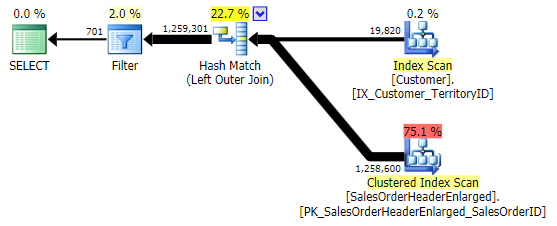
The h.Comment variation does not, since it includes all of the rows where h.Comment IS NULL, as well as all of the rows that did not exist for any customer. I've highlighted the subtle difference in the number of rows in the output after the filter is applied:
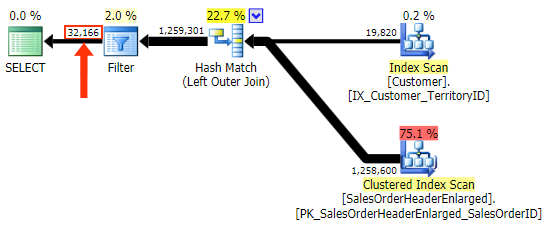
In addition to needing to be careful about column selection in the filter, the other problem I have with the LEFT OUTER JOIN form is that it is not self-documenting, in the same way that an inner join in the "old-style" form of FROM dbo.table_a, dbo.table_b WHERE ... is not self-documenting. By that I mean it is easy to forget the join criteria when it is pushed to the WHERE clause, or for it to get mixed in with other filter criteria. I realize this is quite subjective, but there it is.
EXCEPT
If all we are interested in is the join column (which by definition is in both tables), we can use EXCEPT – an alternative that doesn't seem to come up much in these conversations (probably because – usually – you need to extend the query in order to include columns you're not comparing):
SELECT CustomerID
FROM Sales.Customer AS c
EXCEPT
SELECT CustomerID
FROM Sales.SalesOrderHeaderEnlarged;
This comes up with the exact same plan as the NOT IN variation above:
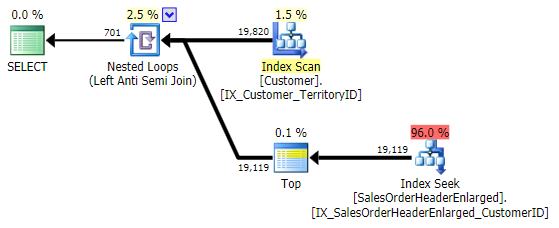
One thing to keep in mind is that EXCEPT includes an implicit DISTINCT – so if you have cases where you want multiple rows having the same value in the "left" table, this form will eliminate those duplicates. Not an issue in this specific case, just something to keep in mind – just like UNION versus UNION ALL.
NOT EXISTS
My preference for this pattern is definitely NOT EXISTS:
SELECT CustomerID
FROM Sales.Customer AS c
WHERE NOT EXISTS
(
SELECT 1
FROM Sales.SalesOrderHeaderEnlarged
WHERE CustomerID = c.CustomerID
);
(And yes, I use SELECT 1 instead of SELECT * … not for performance reasons, since SQL Server doesn't care what column(s) you use inside EXISTS and optimizes them away, but simply to clarify intent: this reminds me that this "subquery" does not actually return any data.)
Its performance is similar to NOT IN and EXCEPT, and it produces an identical plan, but is not prone to the potential issues caused by NULLs or duplicates:
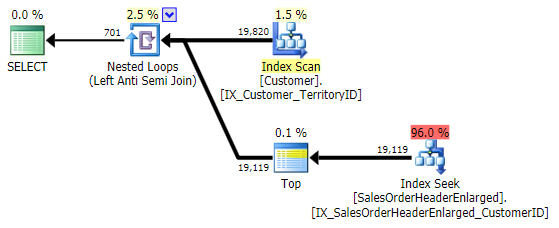
Performance Tests
I ran a multitude of tests, with both a cold and warm cache, to validate that my long-standing perception about NOT EXISTS being the right choice remained true. The typical output looked like this:
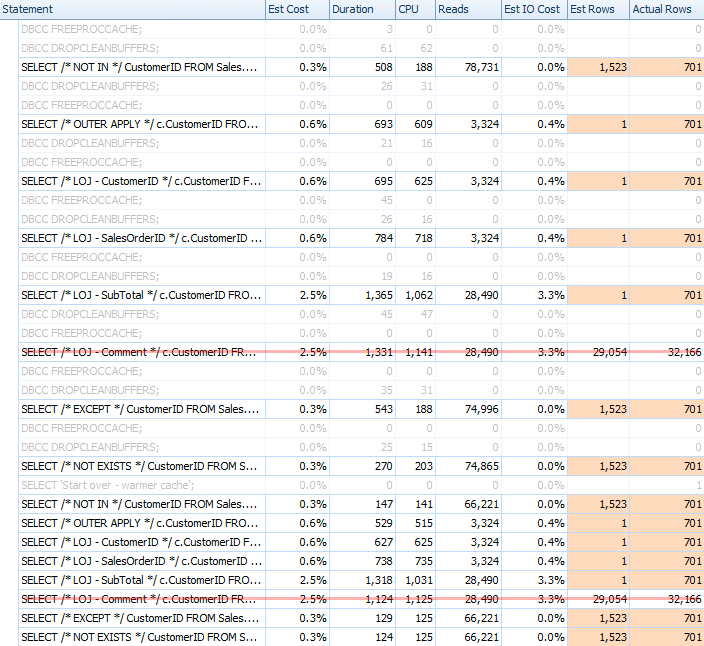
I'll take the incorrect result out of the mix when showing the average performance of 20 runs on a graph (I only included it to demonstrate how wrong the results are), and I did execute the queries in different order across tests to make sure that one query was not consistently benefitting from the work of a previous query. Focusing on duration, here are the results:
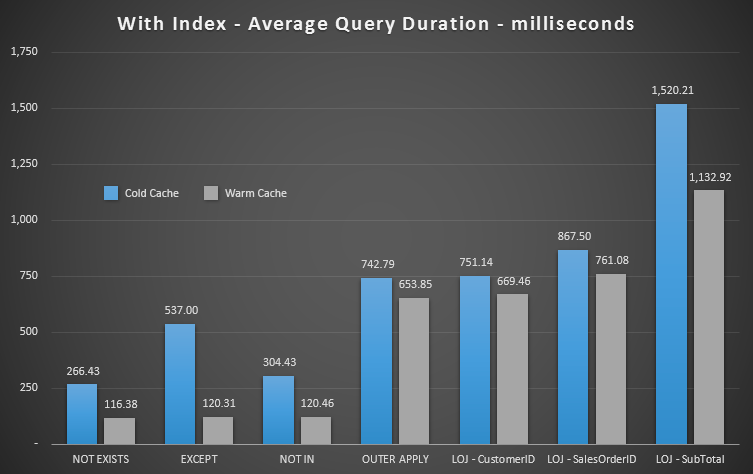
If we look at duration and ignore reads, NOT EXISTS is your winner, but not by much. EXCEPT and NOT IN aren’t far behind, but again you need to look at more than performance to determine whether these options are valid, and test in your scenario.
What if there is no supporting index?
The queries above benefit, of course, from the index on Sales.SalesOrderHeaderEnlarged.CustomerID. How do these results change if we drop this index? I ran the same set of tests again, after dropping the index:
DROP INDEX [IX_SalesOrderHeaderEnlarged_CustomerID]
ON [Sales].[SalesOrderHeaderEnlarged];
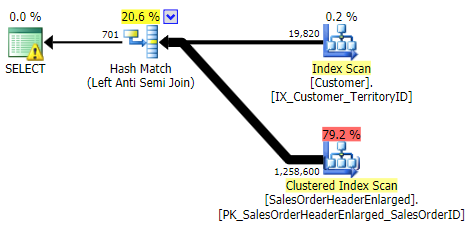
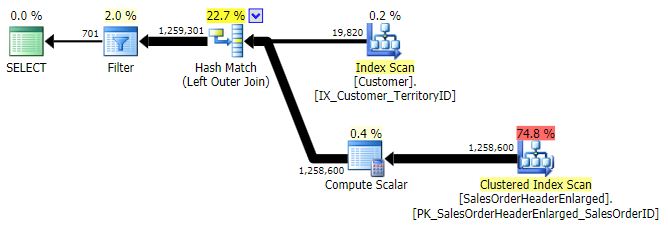
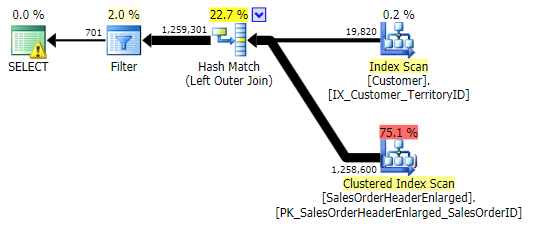
This time there was much less deviation in terms of performance between the different methods. First I'll show the plans for each method (most of which, not surprisingly, indicate the usefulness of the missing index we just dropped). Then I'll show a new graph depicting the performance profile both with a cold cache and a warm cache.
NOT IN, EXCEPT, NOT EXISTS (all three were identical)
OUTER APPLY
LEFT OUTER JOIN (all three were identical except for the number of rows)
Performance Results
We can immediately see how useful the index is when we look at these new results. In all but one case (the left outer join that goes outside the index anyway), the results are clearly worse when we've dropped the index:
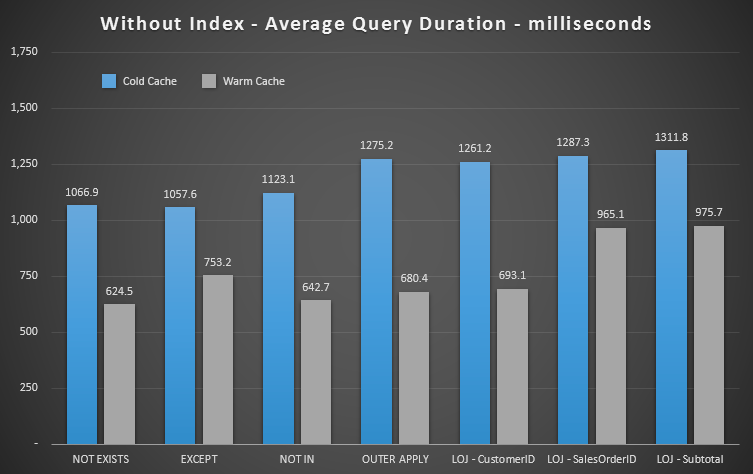
So we can see that, while there is less noticeable impact, NOT EXISTS is still your marginal winner in terms of duration. And in situations where the other approaches are susceptible to schema volatility, it is your safest choice, too.
Conclusion
This was just a really long-winded way of telling you that, for the pattern of finding all rows in table A where some condition does not exist in table B, NOT EXISTS is typically going to be your best choice. But, as always, you need to test these patterns in your own environment, using your schema, data and hardware, and mixed in with your own workloads.
27 thoughts on “Should I use NOT IN, OUTER APPLY, LEFT OUTER JOIN, EXCEPT, or NOT EXISTS?”
Comments are closed.

Great article Aaron. I use the LEFT OUTER JOIN almost exclusively. My assumption was that the NOT EXISTS was creating a more cursor-like row-by-row comparison. I'll definitely be putting this to good use.
Aaron,
Extremely well-documented post. Even a n00b like me can 'get it'. I ran into just this sort of an issue last week where NOT IN produced a bad record set, probably based on NULLS, but I was time-pressed to fix the problem and never went back to see what the root cause was. I fixed it using EXCEPT as it was a little less wordy to code. Nice to know the performance implications around all of these methods. I will definitely use this in the future. Thanks for the article.
Just curious..Why est rows for left join are 1?
The bad estimate in the LOJ case is coming from the filter. I think this happens for the same black box reasons that a UDF will estimate the row count at 1 – the optimizer can't see how many rows won't match the join because of the filter, so makes a swag. It makes a swag in the other direction, but a little farther off, with the non-outer join methods.
Very clear explanation of the scenarios, thank you.
the picture is beautiful, like Performance Results, how can u do it? what tools u use i want to know,thanks!
The full ANSI/ISO Standard SQL has EXCEPT [ALL], INTERSECTION [ALL], as well as UNION [ALL]. As usual, MS is behind by a decade :)
Very well put and confirms my experience as well. Testing where the Outer Table is wide and the target column is not indexed makes a far more dramatic result.
Yes, Joe, it's true – SQL Server has not implemented the full standard. And – gasp – instead they have implemented a lot of features that customers have asked for but that the standard fails to provide. Let us all know when a major vendor provides an RDBMS that implements the standard, the whole standard, and nothing but the standard. :-)
Thanks, the execution plans come from SQL Sentry Plan Explorer; the blue charts come from Excel 2013.
Joe Celko
The open source community is 2 decades behind MS and losing ground. The latest is "Eventually Concurrent" since MSSQL server is the only true ACID compliant database.
One of my "favorites" that I've actually seen used by developers in my company:
I rant and I rave every time I see this, but because the optimizer will sometimes process this as a NOT EXISTS, people think I'm exaggerating the issue.
Most of the variants shown in this post should be collapsed by the optimizer into the best one. NOT-IN is a common requirement for a query, and many different clever and not so clever variants of this are being written every day. They should just all result in the same, optimal plan.
Yes, *should* is the key word there. Sadly we have to deal with an imperfect optimizer and understand its limitations.
There is also another side to consider and that is the number of rows for each of the two tables.
See http://weblogs.sqlteam.com/peterl/archive/2009/06/12/Timings-of-different-techniques-for-finding-missing-records.aspx
However, NOT EXISTS seem to be the best choice in most cases.
useful article
tnx a milion
Good Job, This helped me out alot recently.
Very good article. Thank you!
Is ALL e.g.
WHERE CustomerID ALL
(
SELECT CustomerID
FROM Sales.SalesOrderHeaderEnlarged
);
Any different than NOT IN. It certainly isn't when it comes to NULLs
Ha! I have no idea, Conrad, sorry. I have never used the ALL/ANY syntax, don't know anyone else who does, and didn't even know it existed until I heard it was a substantial component of a recent MS certification exam.
Thank you for Sharing the detailed comparison ! It helped me in one of my performance tuning task. Nicely Explained!!
There is an interesting alternative with OUTER APPLY which, in my case, gave me the best result:
SELECT c.CustomerID
FROM Sales.Customer AS c
OUTER APPLY
(
SELECT Count(*) AS Count
FROM Sales.SalesOrderHeaderEnlarged
WHERE CustomerID = c.CustomerID
) AS h
WHERE h.Count = 0;
It would be interesting to compare performance with the other examples in your article :)
Really Dom? You actually got decent performance from that? See a few posts up where the lunacy of the select count(*) method is highlighted.
You're going to suck up your performance running a count on every row of the table just to see if one row doesn't exist?
If that works best for you, you either only have 3 rows in your table, or some other, more serious issues.
I actually wanted to comment to add that whilst my history bears out with your conclusion in that NOT EXISTS() has almost always been the far quicker method, there is at least one exception: On a driving query with a 5m row table joined with another ~12k rows, checking there's not a match on another table with around 3m rows turned out MUCH quicker using OUTER APPLY() – which was very much unexpected. So don't just jump in and use NOT EXISTS all the time – test it out using a TOP 100 or something, and see where you get the best plan. In this case, NOT EXISTS took 20 times longer than OUTER APPLY.
All 3 tables are indexed to the hilt, with covering indexes as well as specifics set up in the order I need the data back.
This may be because I have to run my check with an expression of values from the driving tables to see if it has already been compiled into table C – namely this monster: 'sale:"'+CAST(l.sale_id AS VARCHAR)+'", itemID:"' + REPLACE(STR(l.sale_id, 10, 0), ' ', '0')+REPLACE(STR(l.soldItemid, 10, 0), ' ', '0') + '"'
Yeah. I inherited a mess from my predecessor. This idiot had obviously never heard of an index, and many tables didn't even have unique constraints. It was a fun time getting indexes going… Sorting that table means correcting it in about 3000 other places the idiot used/abused it in linear code, having seemingly never heard of a DAO.
Even he wouldn't have used select count(*) in a boolean existential check, though.
I know this is an old article but there is one more method I discovered, most useful when the semi-join predicate is more than one column:
SELECT CustomerID
FROM Sales.Customer AS c
CROSS APPLY
(
SELECT c.CustomerID
EXCEPT
SELECT CustomerID
FROM Sales.SalesOrderHeaderEnlarged
);
which neatly combines CROSS APPLY's feature of removing rows with no inner result with EXCEPT's feature of removing matches. The same can be done for EXISTS with an INTERSECT instead.
One fundamental difference from NOT EXISTS is it uses the internal 'Is' comparison operator instead of 'Eq' (makes a difference with nulls, see https://sqlkiwi.blogspot.com/2011/06/undocumented-query-plans-equality-comparisons.html ).
It also usually introduces an extra Inner Join+Constan Scan, which adds a tiny amount to cost.