
Troubleshooting AlwaysOn – Sometimes it takes many sets of eyes
A few weeks ago, I started configuring a demo environment with multiple configurations of AlwaysOn Availability Groups. I had a 5-node WSFC cluster – each node had a standalone named instance of SQL Server 2012, and there were also two Failover Cluster Instances (FCIs) that were set up on top of these nodes. A quick diagram:
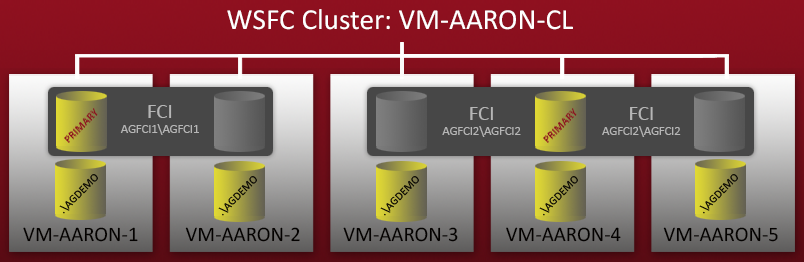
So you can see there are 5 standalone named instances (.\AGDEMO on each node), and then two FCIs – one with possible owners VM-AARON-1 and VM-AARON-2 (AGFCI1\AGFCI1), and then one with possible owners VM-AARON-3, VM-AARON-4 and VM-AARON-5 (AGFCI2\AGFCI2). Now, manually diagramming this out would have to get significantly more complex (more on that later), so I'm going to avoid it for obvious reasons. Essentially the requirement was to have multiple types of AG configurations:
- Primary on an FCI with a replica on one or more standalone instances
- Primary on an FCI with a replica on a different FCI
- Primary on a standalone instance with a replica on one or more FCIs
- Primary on a standalone instance with a replica on one or more standalone instances
- Primary on a standalone instance with replicas on both standalone instances and FCIs
And then combinations (where possible) of synchronous vs. asynchronous commit, manual vs. automatic failover, and read-only secondaries. There are some technical limitations that would limit the permutations possible here, for example:
- Manual failover is necessary with any replica that is on an FCI
- No WSFC node can host – or even be possible owners of – multiple instances, whether standalone or clustered, that are involved in the same Availability Group. You get this error message:
Failed to create, join or add replica to availability group 'MyGroup', because node 'VM-AARON-1' is a possible owner for both replica 'AGFCI1\AGFCI1' and 'VM-AARON-1\AGDEMO'. If one replica is failover cluster instance, remove the overlapped node from its possible owners and try again. (Microsoft SQL Server, Error: 19405)
Most of the scenarios I was trying to represent are not practical in real-world scenarios, but they are largely and theoretically possible. If you haven't guessed by now, this environment is being set up explicitly to test new functionality around Availability Groups that we plan to offer in a future version of SQL Sentry. We gave a sneak peek of some of this technology during our keynote with Fusion-io at the recent SQL Intersection conference in Las Vegas.
Obstacle #1
Setting up Availability Groups using the wizard in SSMS is pretty easy. Unless, for example, you have heterogeneous file paths. The wizard has validation that ensures that the same data and log paths exist on all replicas. This can be a pain if you're using the default data path for two different named instances, or if you have different drive letter configurations (which will often happen when FCIs are involved).
The following folder locations do not exist on the server instance that hosts secondary replica VM-AARON-1\AGDEMO:
P:\MSSQL11.AGFCI2\MSSQL\DATA;
(Microsoft.SqlServer.Management.HadrTasks)
Now it should go without saying that you don't want to set up this scenario in any kind of environment that needs to stand the test of time. Things will go south very quickly if, for example, you later add a new file to one of the databases. But for a test / demo environment, proof of concept, or an environment you expect to be stable for a considerable time, don't fret: you can still do this without the wizard.
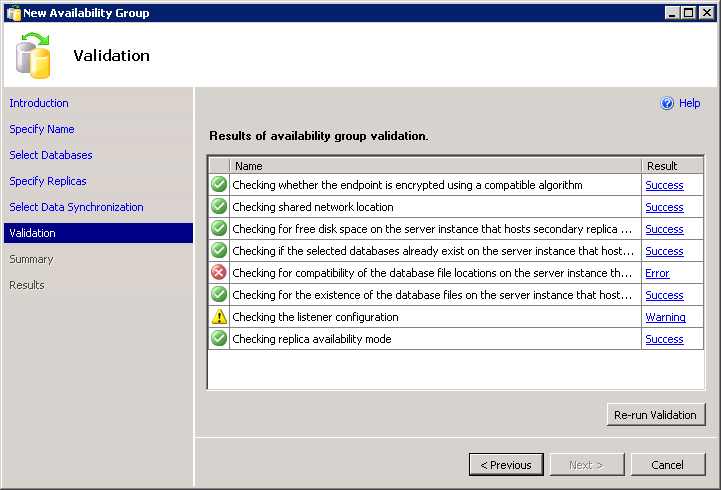
Unfortunately, to add insult to injury, the wizard doesn't let you script it. You can't move past the validation error and there is no Script button:
So this means you need to code it yourself (since the DDL doesn't perform any "helpful" validation for you). If you have other instances where the same paths exist, you can do this by following the same wizard, getting past the validation screen, and then clicking Script instead of Finish, and change the server name(s) and add with WITH MOVE options to the initial restore. Or you can just write your own from scratch, something like this (the script assumes you already have the endpoints and permissions configured, and have all instances have the Availability Groups feature enabled):
-- Use SQLCMD mode and uncomment the :CONNECT commands
-- or just run the two segments separately / change connection
-- :CONNECT Server1
CREATE AVAILABILITY GROUP [GroupName]
WITH (AUTOMATED_BACKUP_PREFERENCE = SECONDARY)
FOR DATABASE [Database1] --, ...
REPLICA ON -- primary:
N'Server1' WITH (ENDPOINT_URL = N'TCP://Server1:5022',
FAILOVER_MODE = MANUAL, AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50, SECONDARY_ROLE(ALLOW_CONNECTIONS = NO)),
-- secondary:
N'Server2' WITH (ENDPOINT_URL = N'TCP://Server2:5022',
FAILOVER_MODE = MANUAL, AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50, SECONDARY_ROLE(ALLOW_CONNECTIONS = NO));
ALTER AVAILABILITY GROUP [GroupName]
ADD LISTENER N'ListenerName'
(WITH IP ((N'10.x.x.x', N'255.255.255.0')), PORT=1433);
BACKUP DATABASE Database1 TO DISK = '\\Server1\Share\db1.bak'
WITH INIT, COPY_ONLY, COMPRESSION;
BACKUP LOG Database1 TO DISK = '\\Server1\Share\db1.trn'
WITH INIT, COMPRESSION;
-- :CONNECT Server2
ALTER AVAILABILITY GROUP [GroupName] JOIN;
RESTORE DATABASE Database1 FROM DISK = '\\Server1\Share\db1.bak'
WITH REPLACE, NORECOVERY, NOUNLOAD,
MOVE 'data_file_name' TO 'P:\path\file.mdf',
MOVE 'log_file_name' TO 'P:\path\file.ldf';
RESTORE LOG Database1 FROM DISK = '\\Server1\Share\db1.trn'
WITH NORECOVERY, NOUNLOAD;
ALTER DATABASE Database1 SET HADR AVAILABILITY GROUP = [GroupName];Obstacle #2
If you have multiple instances on the same server, you may find that both instances can't share port 5022 for their database mirroring endpoint (which is the same endpoint that is used by Availability Groups). This means you will have to drop and re-create the endpoint to set it to an available port instead.
DROP ENDPOINT [Hadr_endpoint];
GO
CREATE ENDPOINT [Hadr_endpoint]
STATE = STARTED
AS TCP ( LISTENER_PORT = 5023 )
FOR DATABASE_MIRRORING (ROLE = ALL);Now I could specify an instance with an endpoint on ServerName:5023.
Obstacle #3
However, once I did this, when I would get to the last step in the script above, after exactly 48 seconds – every time – I would get this unhelpful error message:
The connection to the primary replica is not active. The command cannot be processed.
This had me chasing all kinds of potential issues – checking firewalls and SQL Server Configuration Manager, for example, for anything that would be blocking the ports between instances. Nada. I found various errors in SQL Server's error log:
Database Mirroring login attempt failed with error: 'Connection handshake failed. An OS call failed: (80090303) 0x80090303(The specified target is unknown or unreachable). State 66.'.
A connection timeout has occurred while attempting to establish a connection to availability replica 'VM-AARON-1\AGDEMO' with id [5AF5B58D-BBD5-40BB-BE69-08AC50010BE0]. Either a networking or firewall issue exists, or the endpoint address provided for the replica is not the database mirroring endpoint of the host server instance.
It turns out (and thanks to Thomas Stringer (@SQLife)) that this problem was being caused by a combination of symptoms: (a) Kerberos was not set up correctly, and (b) the encryption algorithm for the hadr_endpoint I had created defaulted to RC4. This would be okay if all of the standalone instances were also using RC4, but they weren't. Long story short, I dropped and re-created the endpoints again, on all the instances. Since this was a lab environment and I didn't really need Kerberos support (and because I had already invested enough time in these issues that I didn't want to chase down Kerberos problems too), I set up all endpoints to use Negotiate with AES:
DROP ENDPOINT [Hadr_endpoint];
GO
CREATE ENDPOINT [Hadr_endpoint]
STATE = STARTED
AS TCP ( LISTENER_PORT = 5023 )
FOR DATABASE_MIRRORING (
AUTHENTICATION = WINDOWS NEGOTIATE,
ENCRYPTION = REQUIRED ALGORITHM AES,
ROLE = ALL);(Ted Krueger (@onpnt) recently blogged about a similar issue as well.)
Now, finally, I was able to create Availability Groups with all of the various requirements I had, between nodes with heterogeneous file paths, and utilizing multiple instances on the same node (just not in the same group). Here is a peek at what one of our AlwaysOn Management views will look like (click to enlarge for a much better overview):
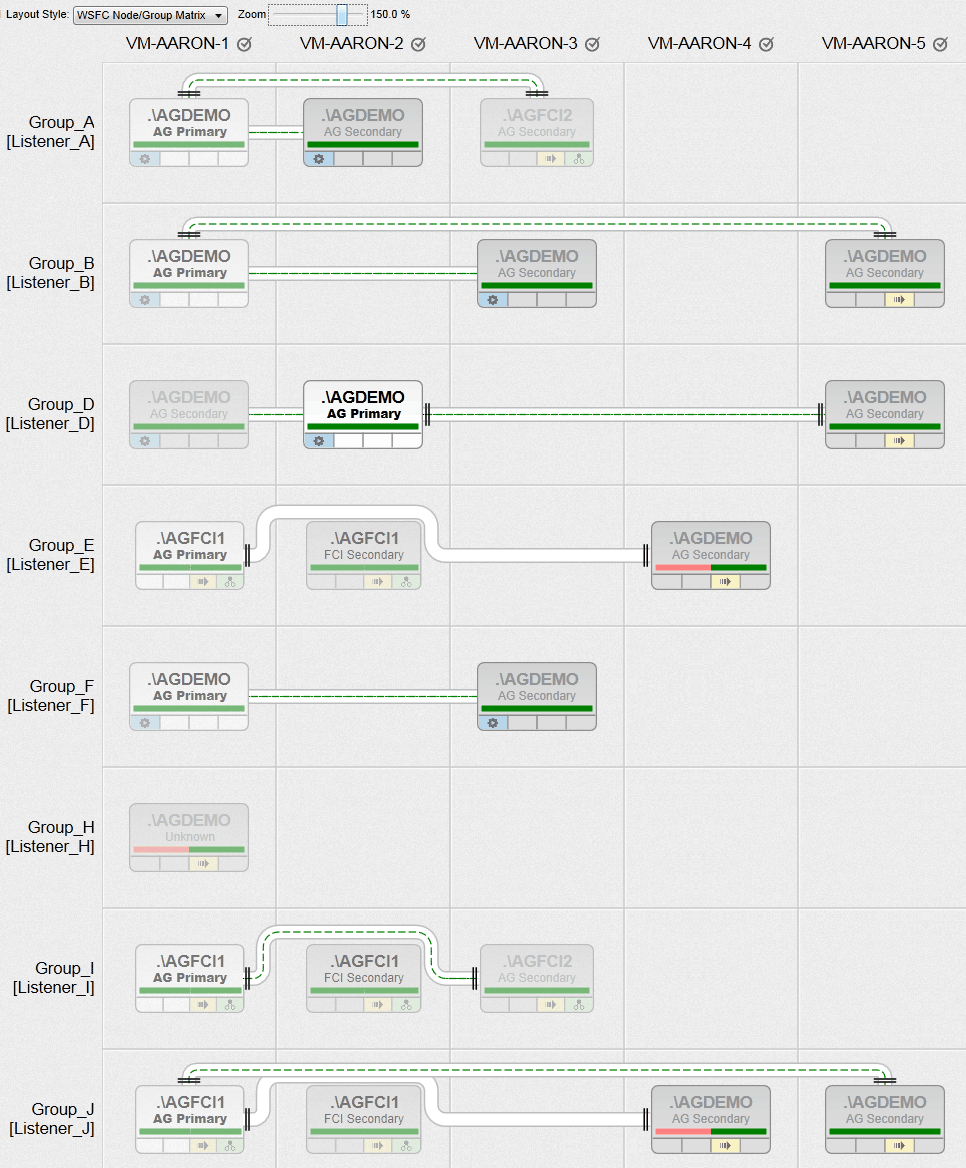
Now, that is just a bit of a tease, and it is fully intentional. I'll be blogging more about this functionality in the coming weeks!
Conclusion
When you spend long enough looking at a problem, you can overlook some pretty obvious things. In this case there were some obvious issues hidden by some downright unintuitive error messages. I want to thank Joe Sack (@JosephSack), Allan Hirt (@SQLHA) and Thomas Stringer (@SQLife) for dropping everything to help a fellow community member in need.
6 thoughts on “Troubleshooting AlwaysOn – Sometimes it takes many sets of eyes”
Comments are closed.

Hey Aaron, Just wanted to let you know this post helped me out tremendously.
I hope all is well.
Brian Walters
Nice post. Regarding Obstacle #1, Can I use ALTER AVAILABILITY GROUP MyAG ADD DATABASE MyDb3; if the AG already exists?
Hi Aaron,
I just want to say that your post helped me on late Friday evening when I was trying to debug a failing mirror set up. Your conclusion that "When you spend long enough looking at a problem, you can overlook some pretty obvious things.". I had different connection_auth_descbetween Primary and mirror and it cost me almost 2 hours until I ended up in your blog.
Really appreciate your help.
Very helpful !! Great explanation.
-Chirag
This is very helpful and I am interested in reading more in your blog "Now, that is just a bit of a tease, and it is fully intentional. I'll be blogging more about this functionality in the coming weeks!" Can you direct me to it?
Actually, Greg wrote up a nice piece on our Always On coverage:
https://blogs.sentryone.com/greggonzalez/sql-sentry-v7-5-a-better-alwayson/