
Don't just blindly create those "missing" indexes!
Kevin Kline (@kekline) and I recently held a query tuning webinar (well, one in a series, actually), and one of the things that came up is the tendency of folks to create any missing index that SQL Server tells them will be a good thing™. They can learn about these missing indexes from the Database Engine Tuning Advisor (DTA), the missing index DMVs, or an execution plan displayed in Management Studio or Plan Explorer (all of which just relay information from exactly the same place):
The problem with just blindly creating this index is that SQL Server has decided that it is useful for a particular query (or handful of queries), but completely and unilaterally ignores the rest of the workload. As we all know, indexes are not "free" – you pay for indexes both in raw storage as well as maintenance required on DML operations. It makes little sense, in a write-heavy workload, to add an index that helps make a single query slightly more efficient, especially if that query is not run frequently. It can be very important in these cases to understand your overall workload and strike a good balance between making your queries efficient and not paying too much for that in terms of index maintenance.
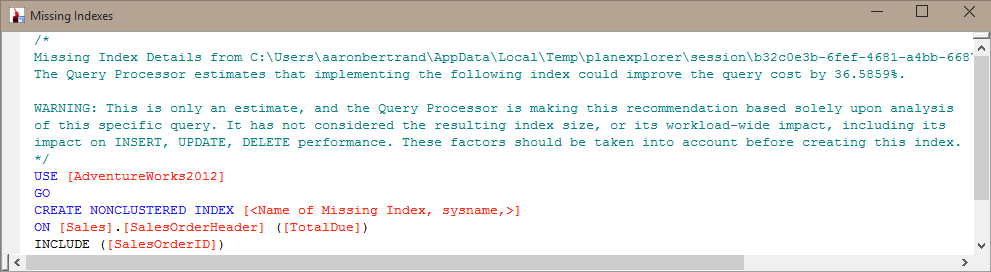
So an idea I had was to "mash up" information from the missing index DMVs, the index usage stats DMV, and information about query plans, to determine what type of balance currently exists and how adding the index might fare overall.
Missing indexes
First, we can take a look at the missing indexes that SQL Server currently suggests:
SELECT
d.[object_id],
s = OBJECT_SCHEMA_NAME(d.[object_id]),
o = OBJECT_NAME(d.[object_id]),
d.equality_columns,
d.inequality_columns,
d.included_columns,
s.unique_compiles,
s.user_seeks, s.last_user_seek,
s.user_scans, s.last_user_scan
INTO #candidates
FROM sys.dm_db_missing_index_details AS d
INNER JOIN sys.dm_db_missing_index_groups AS g
ON d.index_handle = g.index_handle
INNER JOIN sys.dm_db_missing_index_group_stats AS s
ON g.index_group_handle = s.group_handle
WHERE d.database_id = DB_ID()
AND OBJECTPROPERTY(d.[object_id], 'IsMsShipped') = 0;
This shows the table(s) and column(s) that would have been useful in an index, how many compiles/seeks/scans would have been used, and when the last such event happened for each potential index. You can also include columns like s.avg_total_user_cost and s.avg_user_impact if you want to use those figures to prioritize.
Plan operations
Next, let's take a look at the operations used in all of the plans we have cached against the objects that have been identified by our missing indexes.
CREATE TABLE #planops
(
o INT,
i INT,
h VARBINARY(64),
uc INT,
Scan_Ops INT,
Seek_Ops INT,
Update_Ops INT
);
DECLARE @sql NVARCHAR(MAX) = N'';
SELECT @sql += N'
UNION ALL SELECT o,i,h,uc,Scan_Ops,Seek_Ops,Update_Ops
FROM
(
SELECT o = ' + RTRIM([object_id]) + ',
i = ' + RTRIM(index_id) +',
h = pl.plan_handle,
uc = pl.usecounts,
Scan_Ops = p.query_plan.value(''count(//RelOp[@LogicalOp = ''''Index Scan'''''
+ ' or @LogicalOp = ''''Clustered Index Scan'''']/*/'
+ 'Object[@Index=''''' + QUOTENAME(name) + '''''])'', ''int''),
Seek_Ops = p.query_plan.value(''count(//RelOp[@LogicalOp = ''''Index Seek'''''
+ ' or @LogicalOp = ''''Clustered Index Seek'''']/*/'
+ 'Object[@Index=''''' + QUOTENAME(name) + '''''])'', ''int''),
Update_Ops = p.query_plan.value(''count(//Update/Object[@Index='''''
+ QUOTENAME(name) + '''''])'', ''int'')
FROM sys.dm_exec_cached_plans AS pl
CROSS APPLY sys.dm_exec_query_plan(pl.plan_handle) AS p
WHERE p.dbid = DB_ID()
AND p.query_plan IS NOT NULL
) AS x
WHERE Scan_Ops + Seek_Ops + Update_Ops > 0'
FROM sys.indexes AS i
WHERE i.index_id > 0
AND EXISTS (SELECT 1 FROM #candidates WHERE [object_id] = i.[object_id]);
SET @sql = ';WITH xmlnamespaces (DEFAULT '
+ 'N''http://schemas.microsoft.com/sqlserver/2004/07/showplan'')
' + STUFF(@sql, 1, 16, '');
INSERT #planops EXEC sp_executesql @sql;
A friend over on dba.SE, Mikael Eriksson, suggested the following two queries which, on a larger system, will perform much better than the XML / UNION query I cobbled together above, so you could experiment with those first. His ending comment was that he "not surprisingly found out that less XML is a good thing for performance. :)" Indeed.
-- alternative #1
with xmlnamespaces (default 'http://schemas.microsoft.com/sqlserver/2004/07/showplan')
insert #planops
select o,i,h,uc,Scan_Ops,Seek_Ops,Update_Ops
from
(
select o = i.object_id,
i = i.index_id,
h = pl.plan_handle,
uc = pl.usecounts,
Scan_Ops = p.query_plan.value('count(//RelOp[@LogicalOp
= ("Index Scan", "Clustered Index Scan")]/*/Object[@Index = sql:column("i2.name")])', 'int'),
Seek_Ops = p.query_plan.value('count(//RelOp[@LogicalOp
= ("Index Seek", "Clustered Index Seek")]/*/Object[@Index = sql:column("i2.name")])', 'int'),
Update_Ops = p.query_plan.value('count(//Update/Object[@Index = sql:column("i2.name")])', 'int')
from sys.indexes as i
cross apply (select quotename(i.name) as name) as i2
cross apply sys.dm_exec_cached_plans as pl
cross apply sys.dm_exec_query_plan(pl.plan_handle) AS p
where exists (select 1 from #candidates as c where c.[object_id] = i.[object_id])
and p.query_plan.exist('//Object[@Index = sql:column("i2.name")]') = 1
and p.[dbid] = db_id()
and i.index_id > 0
) as T
where Scan_Ops + Seek_Ops + Update_Ops > 0;
-- alternative #2
with xmlnamespaces (default 'http://schemas.microsoft.com/sqlserver/2004/07/showplan')
insert #planops
select o = coalesce(T1.o, T2.o),
i = coalesce(T1.i, T2.i),
h = coalesce(T1.h, T2.h),
uc = coalesce(T1.uc, T2.uc),
Scan_Ops = isnull(T1.Scan_Ops, 0),
Seek_Ops = isnull(T1.Seek_Ops, 0),
Update_Ops = isnull(T2.Update_Ops, 0)
from
(
select o = i.object_id,
i = i.index_id,
h = t.plan_handle,
uc = t.usecounts,
Scan_Ops = sum(case when t.LogicalOp in ('Index Scan', 'Clustered Index Scan') then 1 else 0 end),
Seek_Ops = sum(case when t.LogicalOp in ('Index Seek', 'Clustered Index Seek') then 1 else 0 end)
from (
select
r.n.value('@LogicalOp', 'varchar(100)') as LogicalOp,
o.n.value('@Index', 'sysname') as IndexName,
pl.plan_handle,
pl.usecounts
from sys.dm_exec_cached_plans as pl
cross apply sys.dm_exec_query_plan(pl.plan_handle) AS p
cross apply p.query_plan.nodes('//RelOp') as r(n)
cross apply r.n.nodes('*/Object') as o(n)
where p.dbid = db_id()
and p.query_plan is not null
) as t
inner join sys.indexes as i
on t.IndexName = quotename(i.name)
where t.LogicalOp in ('Index Scan', 'Clustered Index Scan', 'Index Seek', 'Clustered Index Seek')
and exists (select 1 from #candidates as c where c.object_id = i.object_id)
group by i.object_id,
i.index_id,
t.plan_handle,
t.usecounts
) as T1
full outer join
(
select o = i.object_id,
i = i.index_id,
h = t.plan_handle,
uc = t.usecounts,
Update_Ops = count(*)
from (
select
o.n.value('@Index', 'sysname') as IndexName,
pl.plan_handle,
pl.usecounts
from sys.dm_exec_cached_plans as pl
cross apply sys.dm_exec_query_plan(pl.plan_handle) AS p
cross apply p.query_plan.nodes('//Update') as r(n)
cross apply r.n.nodes('Object') as o(n)
where p.dbid = db_id()
and p.query_plan is not null
) as t
inner join sys.indexes as i
on t.IndexName = quotename(i.name)
where exists
(
select 1 from #candidates as c where c.[object_id] = i.[object_id]
)
and i.index_id > 0
group by i.object_id,
i.index_id,
t.plan_handle,
t.usecounts
) as T2
on T1.o = T2.o and
T1.i = T2.i and
T1.h = T2.h and
T1.uc = T2.uc;
Now in the #planops table you have a bunch of values for plan_handle so that you can go and investigate each of the individual plans in play against the objects that have been identified as lacking some useful index. We're not going to use it for that right now, but you can easily cross-reference this with:
SELECT
OBJECT_SCHEMA_NAME(po.o),
OBJECT_NAME(po.o),
po.uc,po.Scan_Ops,po.Seek_Ops,po.Update_Ops,
p.query_plan
FROM #planops AS po
CROSS APPLY sys.dm_exec_query_plan(po.h) AS p;
Now you can click on any of the output plans to see what they're currently doing against your objects. Note that some of the plans will be repeated, since a plan can have multiple operators that reference different indexes on the same table.
Index usage stats
Next, let's take a look at index usage stats, so we can see how much actual activity is currently running against our candidate tables (and, particularly, updates).
SELECT [object_id], index_id, user_seeks, user_scans, user_lookups, user_updates
INTO #indexusage
FROM sys.dm_db_index_usage_stats AS s
WHERE database_id = DB_ID()
AND EXISTS (SELECT 1 FROM #candidates WHERE [object_id] = s.[object_id]);
Don't be alaramed if very few or no plans in the cache show updates for a particular index, even though the index usage stats show that those indexes have been updated. This just means that the update plans aren't currently in cache, which could be for a variety of reasons – for example, it could be a very read-heavy workload and they've been aged out, or they're all single-use and optimize for ad hoc workloads is enabled.
Putting it all together
The following query will show you, for each suggested missing index, the number of reads an index might have assisted, the number of writes and reads that have currently been captured against the existing indexes, the ratio of those, the number of plans associated with that object, and the total number of use counts for those plans:
;WITH x AS
(
SELECT
c.[object_id],
potential_read_ops = SUM(c.user_seeks + c.user_scans),
[write_ops] = SUM(iu.user_updates),
[read_ops] = SUM(iu.user_scans + iu.user_seeks + iu.user_lookups),
[write:read ratio] = CONVERT(DECIMAL(18,2), SUM(iu.user_updates)*1.0 /
SUM(iu.user_scans + iu.user_seeks + iu.user_lookups)),
current_plan_count = po.h,
current_plan_use_count = po.uc
FROM
#candidates AS c
LEFT OUTER JOIN
#indexusage AS iu
ON c.[object_id] = iu.[object_id]
LEFT OUTER JOIN
(
SELECT o, h = COUNT(h), uc = SUM(uc)
FROM #planops GROUP BY o
) AS po
ON c.[object_id] = po.o
GROUP BY c.[object_id], po.h, po.uc
)
SELECT [object] = QUOTENAME(c.s) + '.' + QUOTENAME(c.o),
c.equality_columns,
c.inequality_columns,
c.included_columns,
x.potential_read_ops,
x.write_ops,
x.read_ops,
x.[write:read ratio],
x.current_plan_count,
x.current_plan_use_count
FROM #candidates AS c
INNER JOIN x
ON c.[object_id] = x.[object_id]
ORDER BY x.[write:read ratio];
If your write:read ratio to these indexes is already > 1 (or > 10!), I think it gives reason for pause before blindly creating an index that could only increase this ratio. The number of potential_read_ops shown, however, may offset that as the number becomes larger. If the potential_read_ops number is very small, you probably want to ignore the recommendation entirely before even bothering to investigate the other metrics – so you could add a WHERE clause to filter some of those recommendations out.
A couple of notes:
- These are read and write operations, not individually measured reads and writes of 8K pages.
- The ratio and comparisons are largely educational; it could very well be the case that 10,000,000 write operations all affected a single row, while 10 read operations could have had substantially more impact. This is just meant as a rough guideline and assumes that read and write operations are weighted roughly the same.
- You may also use slights variations on some of these queries to find out – outside of the missing indexes SQL Server is recommending – how many of your current indexes are wasteful. There are plenty of ideas about this online, including this post by Paul Randal (@PaulRandal).
I hope that gives some ideas for gaining more insight into your system's behavior before you decide to add an index that some tool told you to create. I could have created this as one massive query, but I think the individual parts will give you some rabbit holes to investigate, if you so wish.
Other notes
You may also want to extend this to capture current size metrics, the width of the table, and the number of current rows (as well as any predictions about future growth); this can give you a good idea of how much space a new index will take up, which can be a concern depending on your environment. I may treat this in a future post.
Of course, you have to keep in mind that these metrics are only as useful as your uptime dictates. The DMVs are cleared out after a restart (and sometimes in other, less disruptive scenarios), so if you think this information will be useful over a longer period of time, taking periodic snapshots may be something you want to consider.
15 thoughts on “Don't just blindly create those "missing" indexes!”
Comments are closed.

Interesting take on cost estimation of 'missing' indexes. On existing indexes of course we can figure out number of seeks, scans and lookups.
On 'missing' indexes this method is much better than pure speculation and checking for actual Read/Write usage afterwards.
Thanks Kevin.
Perfect .. Awesome description on tackling the missing indexes…
This is an awesome posting and I am looking to find missing indexes when I received email notice. I would like to use this SQL but I'm not sure where to inject alternative 1 within the Plan Ops sql script.
Patti, the alternative replaces everything after
CREATE TABLE #planops(...);in the previous code block (so fromDECLARE @sql ...toINSERT #planops ....Thanks Aaron. A very nice post looking into "missing" index in such a methodic way. Definitely worth sharing with guys in my team.
Thank You Aaron. This is an awesome treat for us.
In Plan Operation step we calculated Scan/Seeks/Updates for indexes in cached plan which existed on tables which were found in missing index report but we never used it in Final Step (putting in all together ) , what would be your suggestion in analyzing that data when making a decision of creating missing index ?
In my case after Plan Operation step using alternative #1 ,in #planops table scan/seek/update columns are either 0 or 1 , though usecount for the plan is high in some cases , I'm running these queries on sql server 2008 r2 sp1 ?
The whole point is that I can't give you a suggestion – there is no magic formula that says you have this many seeks or this many updates, so create or don't create the index. You need to weigh the information, run tests, etc. to determine whether the index is a good idea for your schema, and your query patterns, on your hardware and your environment / version of SQL Server. My post was meant to simply urge you to step back and look at all of the information you have available to you, which I am seeing more of but not enough.
Great post…cuts down on my analysis time
Excellent article! This is exactly the kind of information I would want to use when evaluating indices to create. Way to put it all together!
the second step take for every any still running with out any output ??