
Hekaton with a twist: In-memory TVPs – Part 1
There have been a lot of discussions about In-Memory OLTP (the feature formerly known as "Hekaton") and how it can help very specific, high-volume workloads. In the midst of a different conversation, I happened to notice something in the CREATE TYPE documentation for SQL Server 2014 that made me think there might be a more general use case:

Relatively quiet and unheralded additions to the CREATE TYPE documentation
Based on the syntax diagram, it seems that table-valued parameters (TVPs) can be memory-optimized, just like permanent tables can. And with that, the wheels immediately started turning.
One thing I've used TVPs for is to help customers eliminate expensive string-splitting methods in T-SQL or CLR (see background in previous posts here, here, and here). In my tests, using a regular TVP outperformed equivalent patterns using CLR or T-SQL splitting functions by a significant margin (25-50%). I logically wondered: Would there be any performance gain from a memory-optimized TVP?
There has been some apprehension about In-Memory OLTP in general, because there are many limitations and feature gaps, you need a separate filegroup for memory-optimized data, you need to move entire tables to memory-optimized, and the best benefit is typically achieved by also creating natively-compiled stored procedures (which have their own set of limitations). As I'll demonstrate, assuming your table type contains simple data structures (e.g. representing a set of integers or strings), using this technology just for TVPs eliminates some of these issues.
The Test
You will still need a memory-optimized filegroup even if you aren't going to create permanent, memory-optimized tables. So let's create a new database with the appropriate structure in place:
CREATE DATABASE xtp;
GO
ALTER DATABASE xtp ADD FILEGROUP xtp CONTAINS MEMORY_OPTIMIZED_DATA;
GO
ALTER DATABASE xtp ADD FILE (name='xtpmod', filename='c:\...\xtp.mod') TO FILEGROUP xtp;
GO
ALTER DATABASE xtp SET MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT = ON;
GONow, we can create a regular table type, as we would today, and a memory-optimized table type with a non-clustered hash index and a bucket count I pulled out of the air (more information on calculating memory requirements and bucket count in the real world here):
USE xtp;
GO
CREATE TYPE dbo.ClassicTVP AS TABLE
(
Item INT PRIMARY KEY
);
CREATE TYPE dbo.InMemoryTVP AS TABLE
(
Item INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 256)
)
WITH (MEMORY_OPTIMIZED = ON);If you try this in a database that does not have a memory-optimized filegroup, you will get this error message, just as you would if you tried to create a normal memory-optimized table:
The MEMORY_OPTIMIZED_DATA filegroup does not exist or is empty. Memory optimized tables cannot be created for a database until it has one MEMORY_OPTIMIZED_DATA filegroup that is not empty.
To test a query against a regular, non-memory-optimized table, I simply pulled some data into a new table from the AdventureWorks2012 sample database, using SELECT INTO to ignore all those pesky constraints, indexes and extended properties, then created a clustered index on the column I knew I would be searching on (ProductID):
SELECT * INTO dbo.Products
FROM AdventureWorks2012.Production.Product; -- 504 rows
CREATE UNIQUE CLUSTERED INDEX p ON dbo.Products(ProductID);Next I created four stored procedures: two for each table type; each using EXISTS and JOIN approaches (I typically like to examine both, even though I prefer EXISTS; later on you'll see why I didn't want to restrict my testing to just EXISTS). In this case I merely assign an arbitrary row to a variable, so that I can observe high execution counts without dealing with resultsets and other output and overhead:
-- Old-school TVP using EXISTS:
CREATE PROCEDURE dbo.ClassicTVP_Exists
@Classic dbo.ClassicTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @name NVARCHAR(50);
SELECT @name = p.Name
FROM dbo.Products AS p
WHERE EXISTS
(
SELECT 1 FROM @Classic AS t
WHERE t.Item = p.ProductID
);
END
GO
-- In-Memory TVP using EXISTS:
CREATE PROCEDURE dbo.InMemoryTVP_Exists
@InMemory dbo.InMemoryTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @name NVARCHAR(50);
SELECT @name = p.Name
FROM dbo.Products AS p
WHERE EXISTS
(
SELECT 1 FROM @InMemory AS t
WHERE t.Item = p.ProductID
);
END
GO
-- Old-school TVP using a JOIN:
CREATE PROCEDURE dbo.ClassicTVP_Join
@Classic dbo.ClassicTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @name NVARCHAR(50);
SELECT @name = p.Name
FROM dbo.Products AS p
INNER JOIN @Classic AS t
ON t.Item = p.ProductID;
END
GO
-- In-Memory TVP using a JOIN:
CREATE PROCEDURE dbo.InMemoryTVP_Join
@InMemory dbo.InMemoryTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @name NVARCHAR(50);
SELECT @name = p.Name
FROM dbo.Products AS p
INNER JOIN @InMemory AS t
ON t.Item = p.ProductID;
END
GONext, I needed to simulate the kind of query that typically comes against this type of table and requires a TVP or similar pattern in the first place. Imagine a form with a drop-down or set of checkboxes containing a list of products, and the user can select the 20 or 50 or 200 that they want to compare, list, what have you. The values are not going to be in a nice contiguous set; they will typically be scattered all over the place (if it was a predictably contiguous range, the query would be much simpler: start and end values). So I just picked an arbitrary 20 values from the table (trying to stay below, say, 5% of the table size), ordered randomly. An easy way to build a reusable VALUES clause like this is as follows:
DECLARE @x VARCHAR(4000) = '';
SELECT TOP (20) @x += '(' + RTRIM(ProductID) + '),'
FROM dbo.Products ORDER BY NEWID();
SELECT @x;The results (yours will almost certainly vary):
Unlike a direct INSERT...SELECT, this makes it quite easy to manipulate that output into a reusable statement to populate our TVPs repeatedly with the same values and throughout multiple iterations of testing:
SET NOCOUNT ON;
DECLARE @ClassicTVP dbo.ClassicTVP;
DECLARE @InMemoryTVP dbo.InMemoryTVP;
INSERT @ClassicTVP(Item) VALUES
(725),(524),(357),(405),(477),(821),(323),(526),(952),(473),
(442),(450),(735),(441),(409),(454),(780),(966),(988),(512);
INSERT @InMemoryTVP(Item) VALUES
(725),(524),(357),(405),(477),(821),(323),(526),(952),(473),
(442),(450),(735),(441),(409),(454),(780),(966),(988),(512);
EXEC dbo.ClassicTVP_Exists @Classic = @ClassicTVP;
EXEC dbo.InMemoryTVP_Exists @InMemory = @InMemoryTVP;
EXEC dbo.ClassicTVP_Join @Classic = @ClassicTVP;
EXEC dbo.InMemoryTVP_Join @InMemory = @InMemoryTVP;If we run this batch using SQL Sentry Plan Explorer, the resulting plans show a big difference: the in-memory TVP is able to use a nested loops join and 20 single-row clustered index seeks, vs. a merge join fed 502 rows by a clustered index scan for the classic TVP. And in this case, EXISTS and JOIN yielded identical plans. This might tip with a much higher number of values, but let's continue with the assumption that the number of values will be less than 5% of the table size:
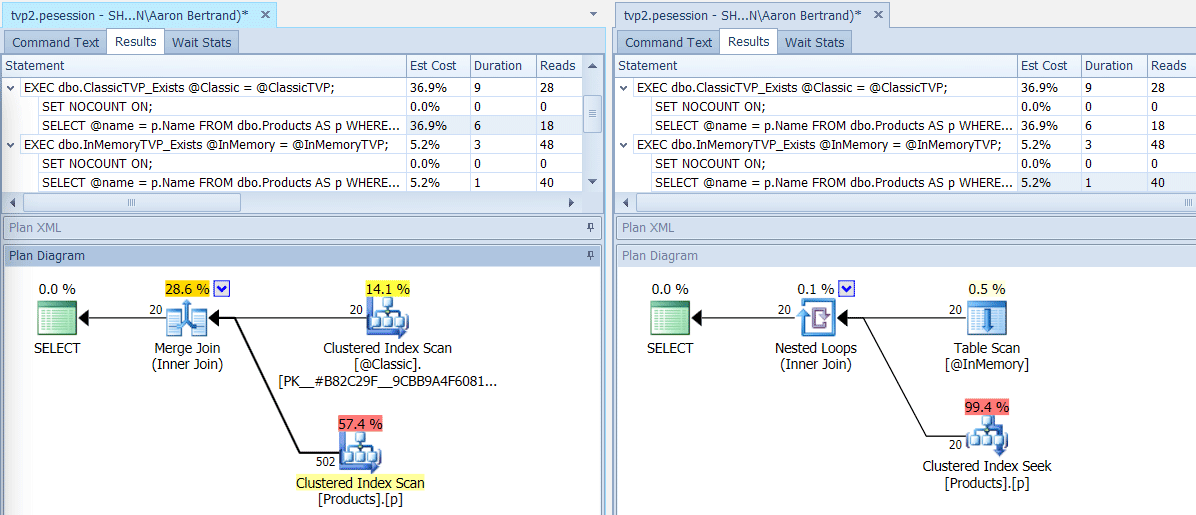 Plans for Classic and In-Memory TVPs
Plans for Classic and In-Memory TVPs
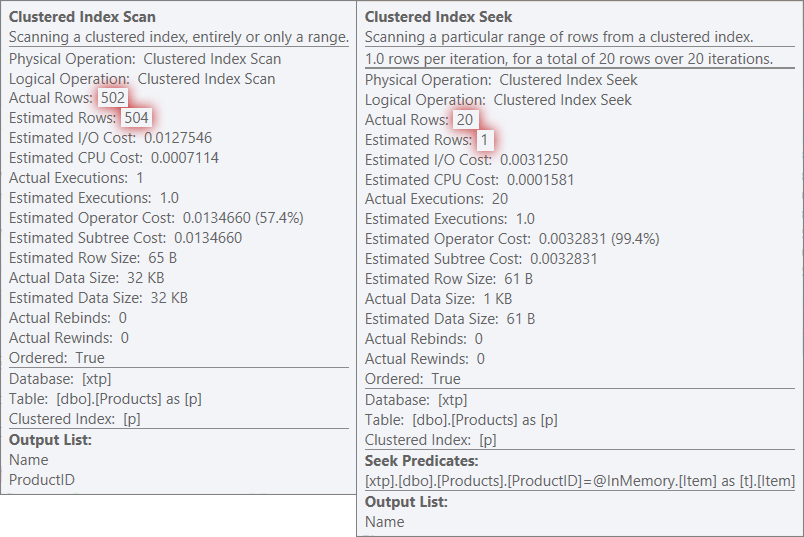 Tooltips for scan/seek operators, highlighting major differences – Classic on left, In-Memory on right
Tooltips for scan/seek operators, highlighting major differences – Classic on left, In-Memory on right
Now what does this mean at scale? Let's turn off any showplan collection, and change the test script slightly to run each procedure 100,000 times, capturing cumulative runtime manually:
DECLARE @i TINYINT = 1, @j INT = 1;
WHILE @i <= 4
BEGIN
SELECT SYSDATETIME();
WHILE @j <= 100000
BEGIN
IF @i = 1
BEGIN
EXEC dbo.ClassicTVP_Exists @Classic = @ClassicTVP;
END
IF @i = 2
BEGIN
EXEC dbo.InMemoryTVP_Exists @InMemory = @InMemoryTVP;
END
IF @i = 3
BEGIN
EXEC dbo.ClassicTVP_Join @Classic = @ClassicTVP;
END
IF @i = 4
BEGIN
EXEC dbo.InMemoryTVP_Join @InMemory = @InMemoryTVP;
END
SET @j += 1;
END
SELECT @i += 1, @j = 1;
END
SELECT SYSDATETIME();In the results, averaged over 10 runs, we see that, in this limited test case at least, using a memory-optimized table type yielded a roughly 3X improvement on arguably the most critical performance metric in OLTP (runtime duration):

Runtime results showing a 3X improvement with In-Memory TVPs
In-Memory + In-Memory + In-Memory : In-Memory Inception
Now that we've seen what we can do by simply changing our regular table type to a memory-optimized table type, let's see if we can squeeze any more performance out of this same query pattern when we apply the trifecta: an in-memory table, using a natively compiled memory-optimized stored procedure, which accepts an in-memory table table as a table-valued parameter.
First, we need to create a new copy of the table, and populate it from the local table we already created:
CREATE TABLE dbo.Products_InMemory
(
ProductID INT NOT NULL,
Name NVARCHAR(50) NOT NULL,
ProductNumber NVARCHAR(25) NOT NULL,
MakeFlag BIT NOT NULL,
FinishedGoodsFlag BIT NULL,
Color NVARCHAR(15) NULL,
SafetyStockLevel SMALLINT NOT NULL,
ReorderPoint SMALLINT NOT NULL,
StandardCost MONEY NOT NULL,
ListPrice MONEY NOT NULL,
[Size] NVARCHAR(5) NULL,
SizeUnitMeasureCode NCHAR(3) NULL,
WeightUnitMeasureCode NCHAR(3) NULL,
[Weight] DECIMAL(8, 2) NULL,
DaysToManufacture INT NOT NULL,
ProductLine NCHAR(2) NULL,
[Class] NCHAR(2) NULL,
Style NCHAR(2) NULL,
ProductSubcategoryID INT NULL,
ProductModelID INT NULL,
SellStartDate DATETIME NOT NULL,
SellEndDate DATETIME NULL,
DiscontinuedDate DATETIME NULL,
rowguid UNIQUEIDENTIFIER NULL,
ModifiedDate DATETIME NULL,
PRIMARY KEY NONCLUSTERED HASH (ProductID) WITH (BUCKET_COUNT = 256)
)
WITH
(
MEMORY_OPTIMIZED = ON,
DURABILITY = SCHEMA_AND_DATA
);
INSERT dbo.Products_InMemory SELECT * FROM dbo.Products;Next, we create a natively compiled stored procedure that takes our existing memory-optimized table type as a TVP:
CREATE PROCEDURE dbo.InMemoryProcedure
@InMemory dbo.InMemoryTVP READONLY
WITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS OWNER
AS
BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english');
DECLARE @Name NVARCHAR(50);
SELECT @Name = Name
FROM dbo.Products_InMemory AS p
INNER JOIN @InMemory AS t
ON t.Item = p.ProductID;
END
GOA couple of caveats. We can't use a regular, non-memory-optimized table type as a parameter to a natively compiled stored procedure. If we try, we get:
The table type 'dbo.ClassicTVP' is not a memory optimized table type and cannot be used in a natively compiled stored procedure.
Also, we can't use the EXISTS pattern here either; when we try, we get:
Subqueries (queries nested inside another query) are not supported with natively compiled stored procedures.
There are many other caveats and limitations with In-Memory OLTP and natively compiled stored procedures, I just wanted to share a couple of things that might seem to be obviously missing from the testing.
So adding this new natively compiled stored procedure to the test matrix above, I found that - again, averaged over 10 runs - it executed the 100,000 iterations in a mere 1.25 seconds. This represents roughly a 20X improvement over regular TVPs and a 6-7X improvement over in-memory TVPs using traditional tables and procedures:

Runtime results showing up to 20X improvement with In-Memory all around
Conclusion
If you're using TVPs now, or you are using patterns that could be replaced by TVPs, you absolutely must consider adding memory-optimized TVPs to your testing plans, but keeping in mind that you may not see the same improvements in your scenario. (And, of course, keeping in mind that TVPs in general have a lot of caveats and limitations, and they aren't appropriate for all scenarios either. Erland Sommarskog has a great article about today's TVPs here.)
In fact you may see that at the low end of volume and concurrency, there is no difference - but please test at realistic scale. This was a very simple and contrived test on a modern laptop with a single SSD, but when you're talking about real volume and/or spinny mechanical disks, these performance characteristics may hold a lot more weight. There is a follow-up coming with some demonstrations on larger data sizes.
5 thoughts on “Hekaton with a twist: In-memory TVPs – Part 1”
Comments are closed.

Hello Aaron,
Great article :-)
Do you know if TxLog activity is involved when use In-Memory TVP?
Thanks
-Klaus
Thanks Klaus, hope to have some details around that in my follow-up post.
Aaron, I see this as a flaw in the implementation, not a benefit. You get an "in this case better plan" because apparently the TVP in memory doesn't get an accurate idea of cardinality of the TVP, as opposed to the standard TVP, which does. You get the same "great for few rows" nested-loop plan if you do this as a classic table variable in ad hoc SQL. But you are hitting 4% of all rows in the table (20/504), so IIRC the optimizer is correct in choosing a table scan as the most efficient mechanism to return that percentage of data. I note you are already doing well more than double the total logical reads here.
If you take this to the opposite extreme and put 95% of the rows in the TVP, my quick testing on SQL 2012 shows the TVP (which accurately estimates 479 rows in the TVP) now outperforms the table variable (which still estimates 1 row in the table var) ad hoc query by over 50% measured by duration.
As you know, the plans you will get with the estimated row 1 disparity can be truly devastating on more complex queries that join to other tables and/or hit larger volumes of data.
You also mention the effect this would have on rotating disks. I think you actually have it backwards. If the data you request isn't in RAM already and has to be fetched from rotating media, the CI index-seek (and nested-loop joins in more complex plans) will likely be MUCH worse in that case because all 20 hits on the clustered index will be RANDOM IO, which could well be significantly more costly from a duration perspective than the sequential IO you would/should get from a single table scan.
Here is my test code:
DECLARE @Classic dbo.ClassicTVP, @i int = 1;
INSERT @Classic(Item) VALUES
(725),(524),(357),(405),(477),(821),(323),(526),(952),(473)
,(442),(450),(735),(441),(409),(454),(780),(966),(988),(512);
DECLARE @name NVARCHAR(50);
SELECT SYSDATETIME()
WHILE @i < 20000
BEGIN
SELECT @name = p.Name
FROM dbo.Products AS p
WHERE EXISTS
(
SELECT 1 FROM @Classic AS t
WHERE t.Item = p.ProductID
);
SET @i +=1
END
SELECT SYSDATETIME()
DECLARE @Classic dbo.ClassicTVP, @i int = 1;
INSERT @Classic(Item) VALUES
(725),(524),(357),(405),(477),(821),(323),(526),(952),(473)
,(442),(450),(735),(441),(409),(454),(780),(966),(988),(512);
DECLARE @name NVARCHAR(50);
SELECT SYSDATETIME()
WHILE @i < 20000
BEGIN
EXEC dbo.ClassicTVP_Exists @Classic = @Classic;
SET @i +=1
END
SELECT SYSDATETIME()
Thanks Kevin, I definitely tried to make sure to be clear that this is not an "all scenarios" win, but rather in this limited use case, and that if your input factors remain consistent, it is worth testing. Nowhere did I suggest "here is the new way to do things; don't even test for yourself." In fact I already have a follow-up post in progress that shows several scenarios (like the one you mentioned) that are the *wrong* candidates for this type of change. This post was meant to target a pretty common scenario – you're trying to find a very *small* percentage of the table, not 95% of it. For that situation I'd rather exclude the 5% than match the 95%.
I wonder if this particular short-coming is on the queue to be addressed by RTM. I strongly suspect this is in the realm of "not important enough" to merit additional attention to get it to grab the cardinality like TVPs seem do in non-in-memory constructs.
The estimated-one-row "feature" a variety of constructs get with the SQL Server optimizer is something you can actually take advantage of in some rare cases (such as your example here), but I have seen it cause really bad problems FAR more times than it has been even remotely beneficial! :-)
I look forward to the rest of the story!